How it works
AI that works in the field — not just in demos.
Triplet is not built for demos. It runs in live operations, powered by a shared set of engines.
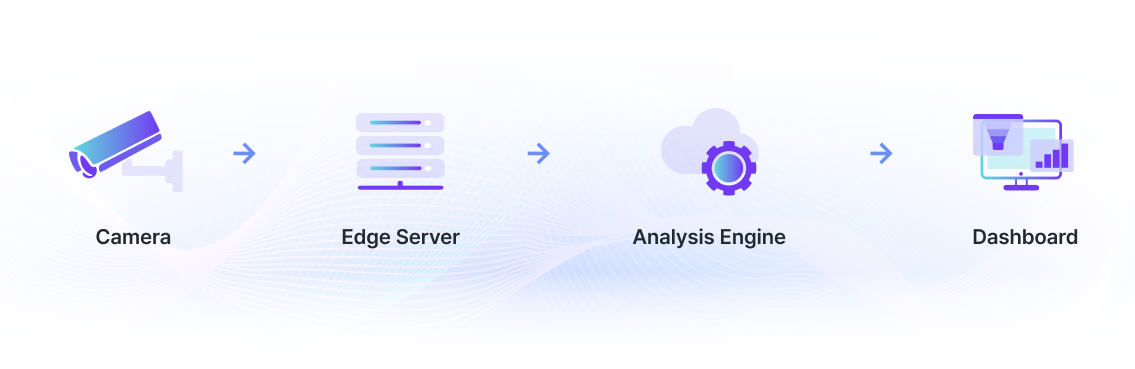
Real-time. Reliable. Built to scale.
We don't just collect data. We turn it into decisions.
Technology doesn't replace decisions — it makes them defensible.
From movement to decisions
How real-world movement becomes data — and data becomes action.
1. Space
Cameras and sensors capture movement as it happens.
 tech_step_01.png
tech_step_01.png
2. Structure
Raw signals are de-identified and structured for analysis.
 tech_step_02.png
tech_step_02.png
3. Decision
Reports and alerts that drive action — on the ground.
 tech_step_03.png
tech_step_03.png

Six engines.
One understanding of space.
Triplet is not one algorithm — it's a set of engines that work together. Deploy them independently or as a unified pipeline.
Triplet DeepLounge Engine ❶
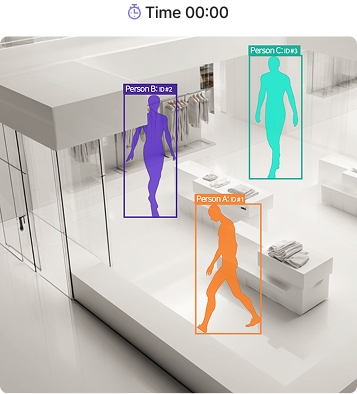
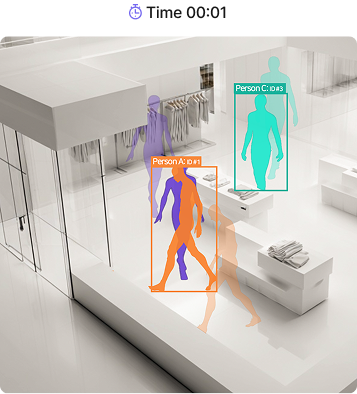
Real-time trajectory tracking
- Persistent IDs across frames
- Paths, dwell time, and congestion — captured
- Stable tracking under occlusion
Triplet tracks dozens of people frame by frame. Each person receives a unique ID that holds from the moment they appear until they leave. Detection finds a person in each frame independently. Tracking connects them through time — answering "who in this frame matches whom in the last?" That continuity is what makes path analysis, dwell time, and live congestion measurement possible. IDs stay stable even under occlusion, rapid motion, or when a person is briefly hidden behind structures. Proven at scale: 6,000 m² (1,800 pyeong) with 100+ cameras.
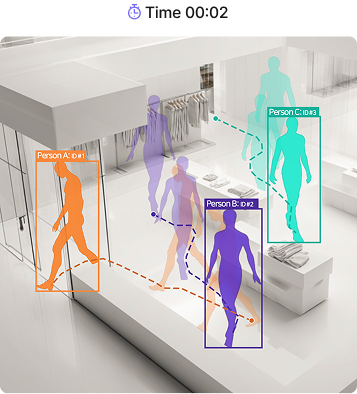
Triplet DeepLounge Engine ❷
One person, every camera
- Link routes across cameras
- Count unique visitors, not duplicates
- No face recognition required
When a person leaves one camera's view, Re-ID finds them again in the next — and stitches the route into a single path. Instead of facial recognition, Triplet compares appearance vectors: clothing color, body shape, gait. No facial data is stored. Without Re-ID, the same person captured by multiple cameras is counted as many different people. With Re-ID, those paths merge into one — producing an accurate unique visitor count. Recognition holds even across blind zones between cameras.
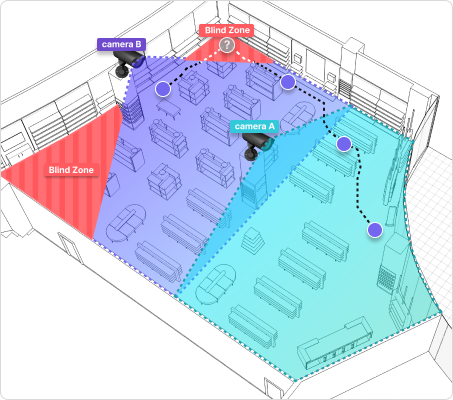

Triplet DeepLounge Engine ❸
Attributes without identity
- Estimate visitor attributes — store nothing
- Full-body recognition, not just faces
- Works in any camera setup
Triplet estimates gender, age, and demographics in real time — without storing facial images. Once inference completes, the source footage and facial data are discarded. Privacy compliance is built in, not bolted on. Unlike face-only systems, Triplet reads the full body — face, torso, and lower body together. This means classification still works when faces are covered by masks, crowds, or side angles, which is why real-world accuracy stays high. Optimized for fisheye and top-view cameras, it deploys directly into standard ceiling-mounted CCTV environments.

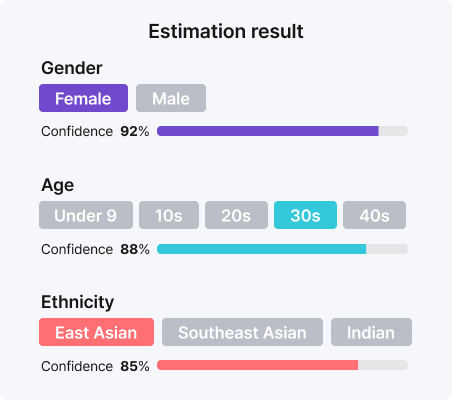
Triplet DeepLounge Engine ❹
Zero-shot risk detection
- Context-aware video recognition
- Define risks in natural language
- Detect risks never seen before
VLM reads scenes through language. Traditional computer vision models only detect pre-registered classes — helmets, vests, uniforms. VLM detects behavior defined in plain language, such as "a person using a phone while walking." Images are broken into small units and converted into visual vectors. A projection layer aligns those vectors with a form the language model can understand. A large language model then combines visual and textual knowledge to interpret the scene's meaning. This engine powers Triplet OZO (safety management) and Triplet KODA (sports officiating).
1. Input & tokenization

2. Visual embedding

3. Visual-language alignment
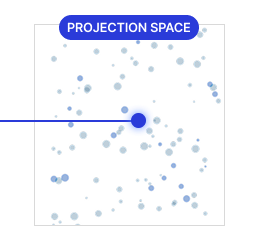
4. Language interpretation

Triplet DeepLounge Engine ❺
Spatial insight, on demand
- Cross-analyze spatial and business data
- Ask in plain language. Get answers.
- Built for operators, not analysts
Triplet's RAG engine already knows your space — dwell time, paths, congestion. Upload your own data on top: sales figures, customer surveys, operations logs. Ask questions in plain language. Get cross-analyzed answers in seconds. "Where is dwell high but sales conversion low?" "Which paths bottleneck at peak hours?" Questions that used to require a data analyst — now answered on the floor, in real time.
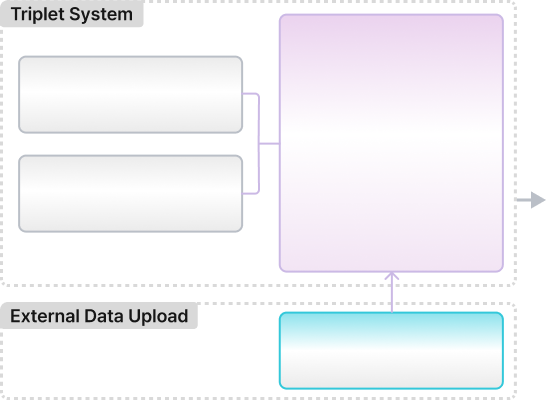
Triplet DeepLounge Engine ❻
Search video with text
- Search footage with a description
- No facial database required
- Reconstruct movement paths automatically
Search hours of CCTV footage with a single line of description. Enter something like "red top, hat, black pants" — the kind of description taken when a missing person is reported — and VLM returns every matching segment, ranked by similarity. No facial database required. Works from day one. Hundreds of hours are scanned in seconds, and the person's camera-to-camera path is reconstructed in time order. Deployed directly for missing person search, suspect tracking, and verifying entry history by appearance.

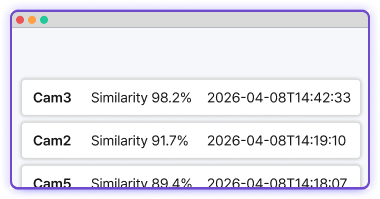
Missing person search
Search parks, trails, and facilities simultaneously from a reported description. Hundreds of hours, scanned in seconds.

Suspect tracking
Reconstruct a person's path across cameras from appearance alone. Works even without facial records.


Security isn't a feature.
It's the baseline.
Built for public, industrial, and large-scale environments — with security and de-identification from day one.
- No raw video stored. De-identified data only.
- Masking and filtering at the edge
- On-premise and private cloud ready
- Ready for government, pilots, and PoCs
Why Triplet works
What works in a demo is not what works in production.
Same technology, different outcomes. Triplet is built on years of solving problems encountered in real deployments — not in controlled scenarios. That experience is what sharpens accuracy, handles edge cases, and keeps the system running when others stop.
Triplet Challenge ❶
Universal post-processing. Any environment.
Off-the-shelf SOTA models break in real environments. Dense crowds, fast motion, unusual angles — and detection itself fails. IDs switch. Trajectories drop.

Our approach
Triplet holds trajectories — even when detection doesn't. Our proprietary post-processing keeps IDs stable through noisy detection. Each deployment is tuned to local density, speed, and camera conditions. Proven at 6,000 m² with 100+ cameras.
Triplet Challenge ❷
Validated where it's hardest — uniforms and night.

Real environments don't look like public datasets. People occlude each other. Lighting shifts. Camera angles vary. And when dozens of people wear the same uniform at once, color and pattern stop working as identifiers altogether.
Our approach
When clothing matches, Triplet reads motion instead of color — gait, body shape, and trajectory. We collect field data directly and train feature representations optimized for each environment. It works in low light. Re-ID performance is preserved even on IR (infrared) footage, so operations run 24/7 in sites with no lighting.
Triplet Challenge ❸
A 100-pixel figure. Dozens of cameras. In real time.
Field CCTV is installed to cover wide areas. Even in FHD, most people appear as objects under 100 pixels — expressions, hand gestures, and posture detail all disappear. The visual features a VLM needs to understand behavior simply aren't there. Processing dozens of streams at once compounds the problem.

Our approach
Triplet made real-time detection work under these conditions. Instead of processing the whole frame, we track suspicious behavior first — then run VLM only on that person. By selecting only the targets and moments that matter, compute drops sharply and the resolution problem is solved at the same time.
Triplet Challenge ❹
Beyond detection — precise counts with sub-1 MEA.

A VLM can detect a specific behavior. But when the same event spans multiple frames in rapid succession, deciding whether it counts as one event or many is a separate problem. Without that judgment, event counts are unreliable.
Our approach
Triplet doesn't stop at detection — it counts accurately. Post-processing groups repeated detections into single events, removing duplicates and leaving only actual occurrences. Mean Event Accuracy (MEA) stays at or below 1. That's beyond analytics — it's data reliable enough for official review.
96 × 96
Triplet always starts with the same question.
"What needs to change in this space — right now?"
What does your space need to decide?
Data without interpretation disappears. Turn your spatial signals into operational answers — with Triplet.
Contact us